PII boundaries for document retrieval pilots
- 26 May 2026
- In Blog, Governance
- ~8 min read
What are PII boundaries for document retrieval?
PII boundaries for document retrieval are the rules for which files and fields may be indexed, how identifiers are separated from sensitive narrative, and how long query logs are kept before a pilot touches real mailboxes or attachments.
Who this guide is for
Sponsors, legal, and IT leads in regulated or privacy-sensitive operations (health, finance, HR-heavy SMEs). Combine with access control for internal Q&A.
Boundary checklist
- Classify sources: internal only, customer data, regulated narrative.
- Exclude draft, personal, or archived folders by default unless approved.
- Keep payroll, clinical, or legal free text in source systems when possible.
- Set log retention and redaction for prompts that include document excerpts.
- Obtain written sign-off from legal or privacy before production indexing.
Customer-facing paths
If retrieved text can surface in outbound messages, add human-in-the-loop gates and test in staging before widen.
How Yarli applies boundaries
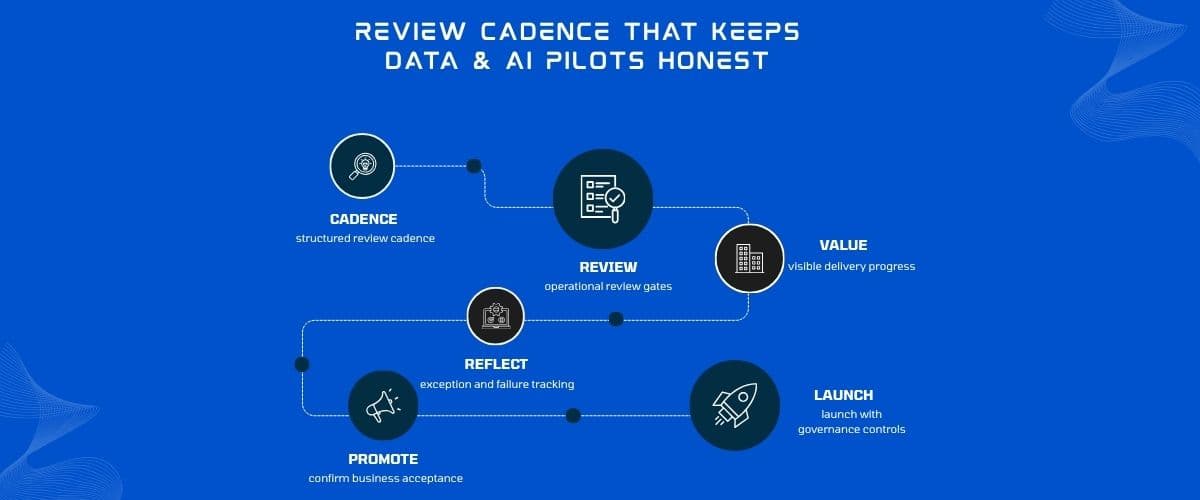
We document boundaries in pilot scope on Knowledge base work and review them each cycle on review cadence.
Published by Yarli Data, Sydney. Australia-wide delivery for operational Data and AI pilots.
Set document retrieval boundaries
Describe document sources and regulated data — we will propose indexing boundaries and review gates before go-live.